Three months ago I had never written a Python agent in my life. I knew DAX, data modelling, and governance — but agentic AI was completely new territory. I built this anyway, because I kept seeing a problem I wanted to solve. I’m calling it the Power BI DAX Agent, and I’ve made it free for anyone to use.
This article explains why I built it, who it is designed for, how it compares to other AI-powered approaches to Power BI development, and where it’s heading next.
Why I Built This
The problem I kept running into wasn’t with Power BI itself. It was with the context in which most companies use it.
In a mid-size company, there is usually one person who “does Power BI.” That person is not necessarily a dedicated BI developer. They are a finance manager who learned DAX from YouTube, or an ops analyst who built a dashboard that got promoted to the company’s main reporting tool, or an IT generalist who maintains a growing semantic model alongside everything else they do.
These people face a specific and under-discussed problem: they need to change things without breaking things.
They’re not looking for ways to build faster. They’re worried about what happens when they rename a column that fifteen measures depend on. They don’t know if the measure they’re about to create already exists under a slightly different name. They have no way of knowing the downstream impact of a change before they make it.
Existing AI tools for Power BI don’t really solve this problem. Most of them are designed to make senior developers faster — which is valuable, but it’s not the same thing.
So I built something designed around a different principle: confidence over speed. I built it with Claude Code, drawing on ideas from Kalina Ivanova and Kurt Buhler’s work in the Power BI agentic development space.
What the Agent Actually Does
The Power BI DAX Agent is a locally-running web application. You open it in your browser, point it at your Power BI model file, and describe the measure you need in plain English. The agent generates validated DAX using only your actual tables and columns, checks for duplicates, and asks for your approval before saving anything.
Here is the end-to-end flow:
1. Load your model with a sanitisation review
Before anything reaches the AI, the agent scans your model file and strips sensitive metadata — database connection strings, file paths, email addresses, SharePoint URLs, and similar content. You see exactly what was found and what was masked. Nothing proceeds until you explicitly approve the clean version. The idea for this gate came from Kalina Ivanova, who built a standalone PowerShell script to scrub sensitive metadata from TMDL files before sharing with AI tools. I took that concept and embedded it directly into the agent workflow. Kurt Buhler’s power-bi-agentic-development repository also shaped how I thought about safe agentic patterns for Power BI more broadly.
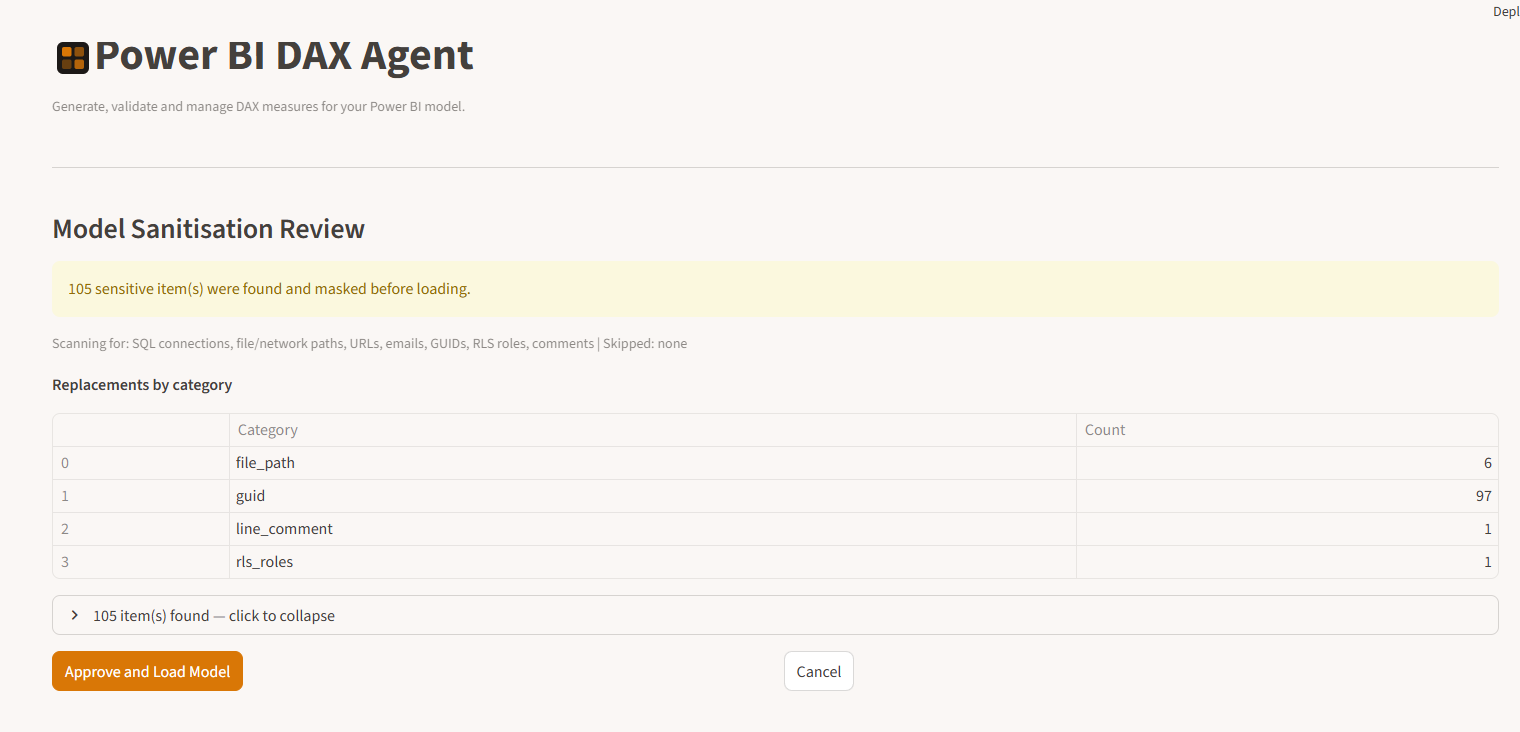
The sanitisation review screen — you see exactly what was found and masked before anything is loaded into the agent.
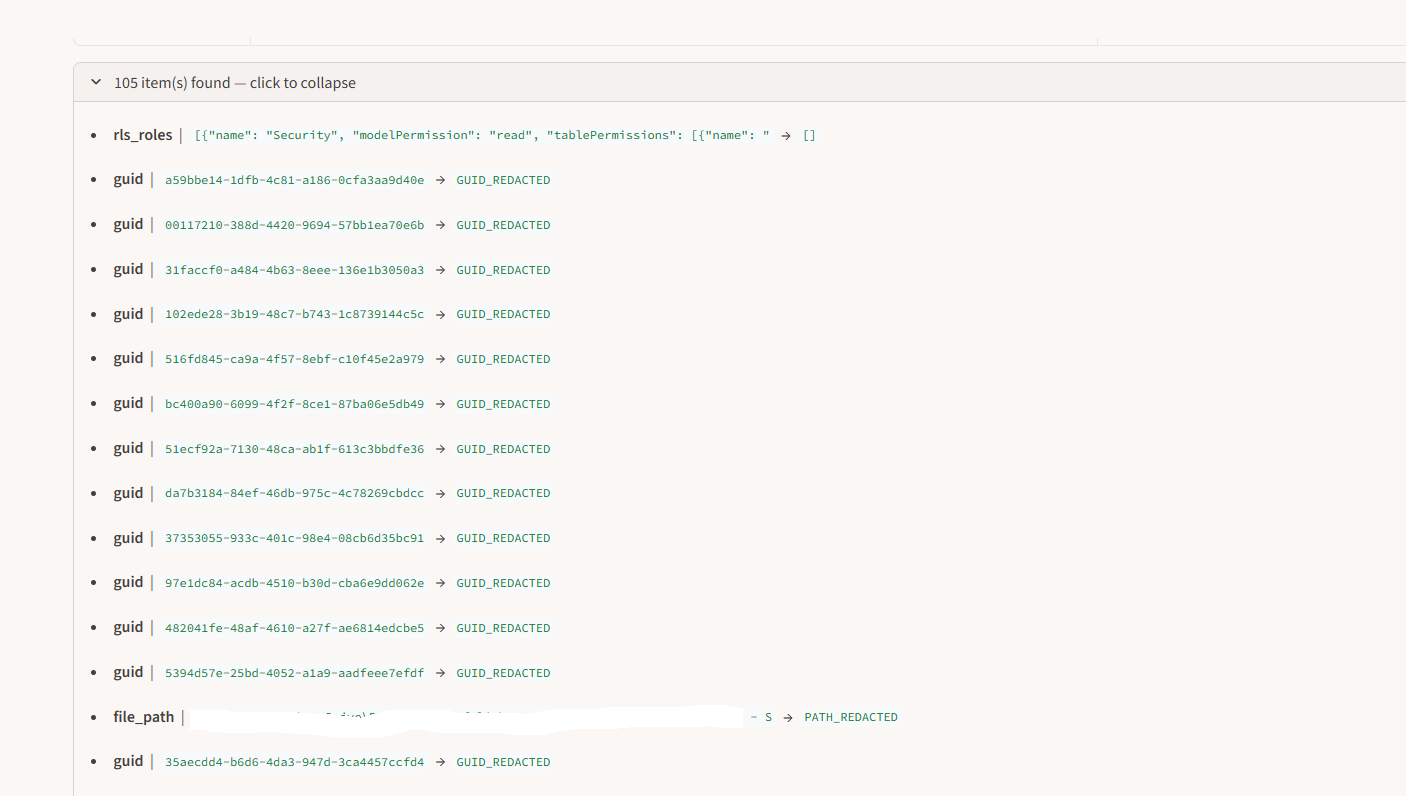
The expandable items list shows each masked value and what it was replaced with.
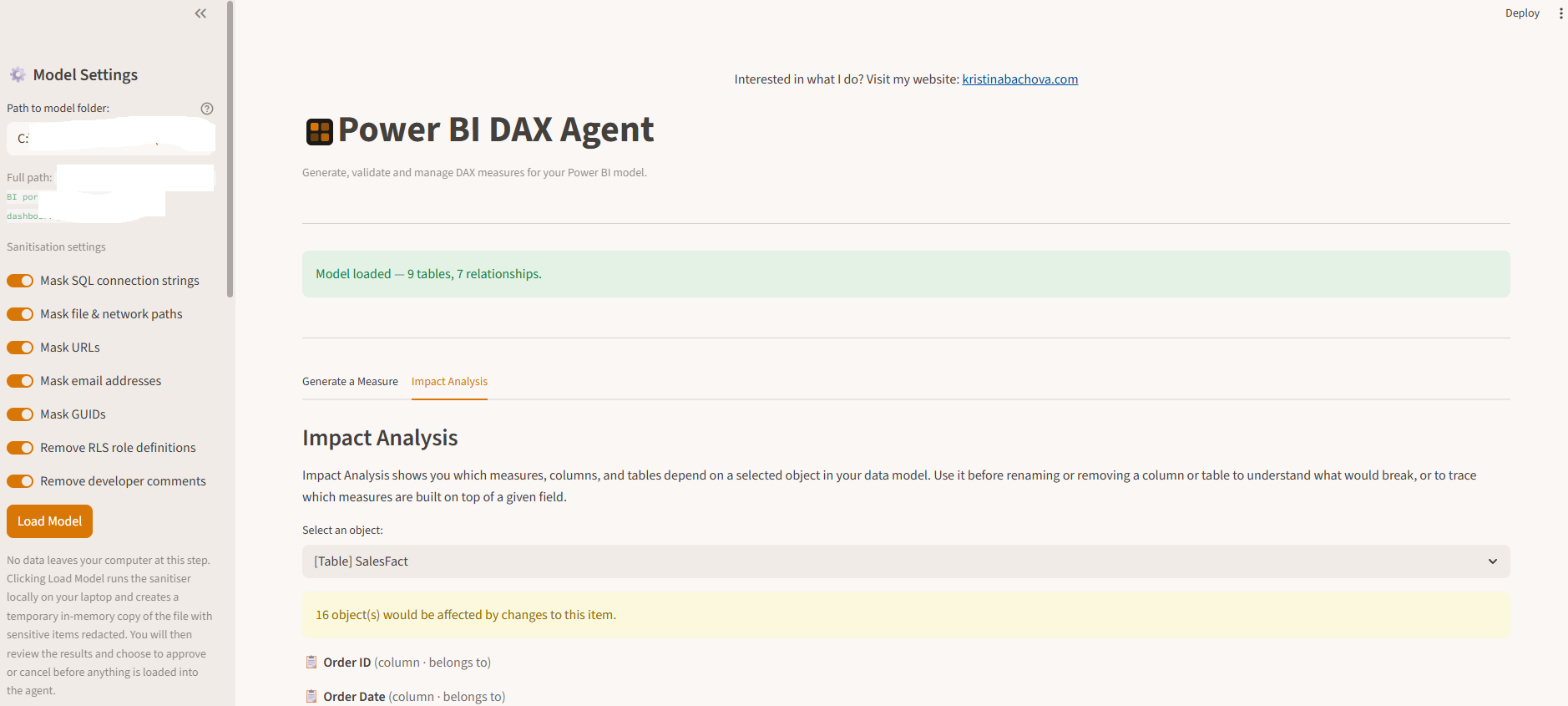
2. Explore your schema and understand dependencies
Once the model loads, a lineage graph is built automatically. You can select any table, column, or measure and see everything that depends on it. If you’re about to change a column, the agent tells you exactly which measures would be affected. You know the blast radius before you touch anything.
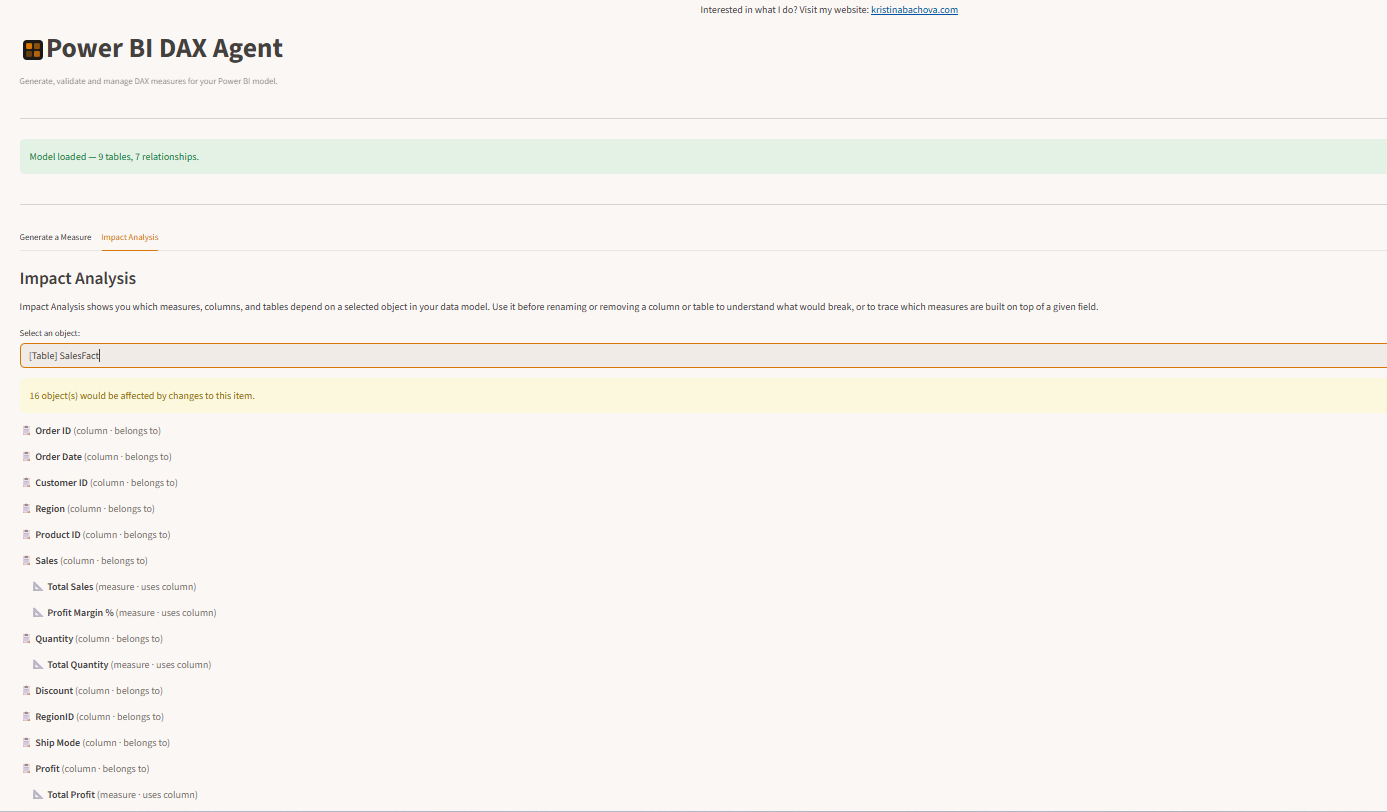
Impact Analysis — select any table, column, or measure to see everything that depends on it.
3. Generate DAX with a human approval gate
You describe what you need. The agent checks your measure library first — if a similar measure already exists, it surfaces it and asks if you want to use it instead. If nothing matches, it generates DAX, validates it structurally and semantically, and presents it for your review. You approve it or reject it. Only approved measures are saved.
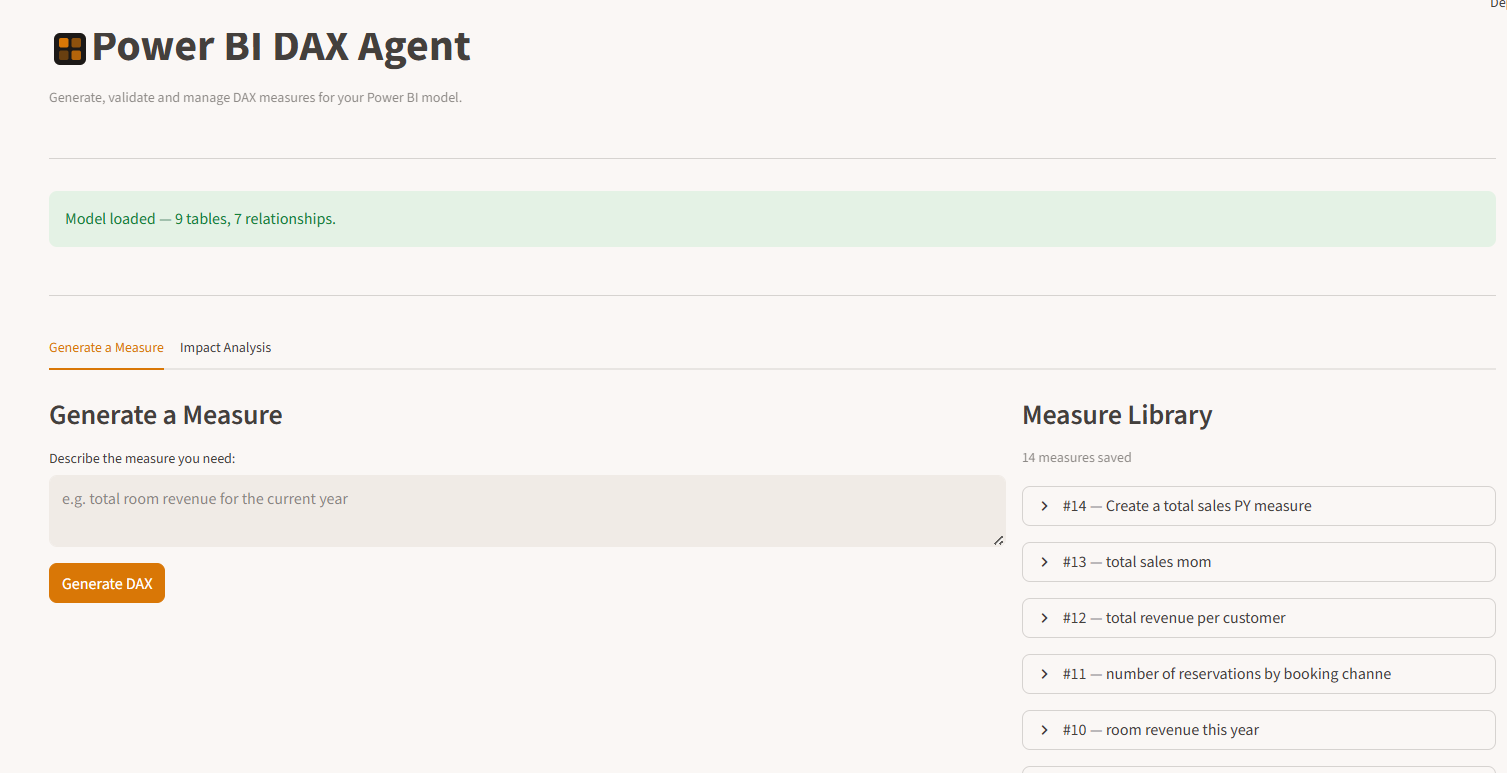
The Generate a Measure tab — describe what you need in plain English, review the output, and approve or reject it.
The full interface — model settings and sanitisation options in the sidebar, the main workspace on the right.
4. Build an institutional measure library
Every approved measure is saved to a persistent library with the original request, the DAX, how many attempts it took to generate, and a timestamp. Over time this becomes a searchable record of every measure your team has generated, which also feeds back into the duplicate detection.
Who This Is For
The primary audience is anyone managing Power BI — particularly in EU markets where data governance and GDPR compliance are genuine daily concerns, not theoretical ones.
More specifically, it is designed for:
- The solo BI person who owns the Power BI environment and needs a reliable assistant that works within guardrails, not around them
- Freelance Power BI consultants who work across multiple client environments and want a consistent, governed workflow for measure development
- Small BI teams where junior analysts are generating measures but a senior developer wants oversight before anything reaches the production model
- Companies in regulated industries — healthcare, financial services, legal — where every change to a reporting environment needs to be traceable and auditable
That said, this is not limited to that audience. Any Power BI developer who values a governed workflow over an unconstrained one may find it useful — especially for client-facing or production environments where mistakes are expensive.
How This Compares to MCP + Copilot and VS Code + Copilot
This is the question I expect most from people who already use AI tools for Power BI development, so I want to address it directly.
Microsoft’s Power BI Modeling MCP Server
Microsoft recently released a Power BI Modeling MCP Server that lets AI assistants like GitHub Copilot or Claude talk directly to a running Power BI Desktop instance. You can ask it to create measures, rename tables, build relationships, and refactor your model through natural conversation in VS Code or Claude Code.
This is genuinely impressive technology and I use it myself for exploratory work. But it is designed for a developer workflow, and it makes some assumptions that are not safe in a business context:
- It writes changes directly to your open model. There is an undo function, but there is no approval gate, no audit trail, and no blast radius analysis before a change is made.
- It sends your full model schema to the AI — including connection strings, file paths, and RLS definitions — without a sanitisation step.
- It requires Power BI Desktop to be open and running. It cannot work from a model file alone.
- It has no persistent memory. Nothing is remembered between sessions. There is no measure library, no duplicate detection, no lineage graph.
For a senior developer working on their own environment who knows what they are doing: MCP is fast and powerful. For a business context where multiple people touch a model and changes need to be traceable: it is missing the safety layer.
VS Code + GitHub Copilot (without MCP)
This is the more general version of the developer assistant workflow — using Copilot in VS Code to help write DAX, Power Query M code, or TMDL. It is useful for developers who are already comfortable in a code editor and want AI assistance inline.
The same considerations apply. This is a tool that makes developers faster. It does not address governance, impact analysis, or the non-technical user.
Where the Power BI DAX Agent Sits
The DAX Agent is not trying to compete with MCP for the developer use case. It is solving a different problem for a different audience.
|
Power BI DAX Agent |
MCP + Copilot |
| Designed for | Business context, governed workflow | Developer productivity |
| User profile | Finance manager, solo BI person, consultant | Senior BI developer |
| Requires VS Code | No — runs in a browser | Yes |
| Sanitisation gate | Built in | Not included |
| Human approval gate | Mandatory | Not included |
| Audit trail | Full history | Session only |
| Duplicate detection | Built in | Not included |
| Lineage and impact analysis | Built in | Not included |
| Works without Power BI Desktop open | Yes | No |
| Persistent measure library | Yes | No |
The honest summary: if you are a senior BI developer who lives in VS Code and knows exactly what you are doing, MCP is probably a better fit for your daily workflow. If you are managing Power BI in a business context where changes need to be safe, traceable, and understandable to non-technical stakeholders — this is built for you.
The Data Protection Question
One question I get asked immediately whenever AI and Power BI are mentioned together is: what data actually leaves my machine?
This is the right question to ask, and I want to answer it precisely.
When you load a model into the agent, the following happens on your machine only:
- The raw model file is read from your local disk
- The sanitisation scan runs locally — finding and masking connection strings, paths, emails, URLs, and any other sensitive metadata you have configured
- You review the sanitisation report in your browser (which is running at localhost — your machine talking to itself)
- You approve the clean version
The first and only time anything leaves your machine is when you type a measure request and click Generate. At that point, the sanitised schema (table names, column names, measure names, data types, relationships) and your plain English request are sent to the Anthropic API.
What never leaves your machine: actual data values, database connection strings, file paths, email addresses, RLS role definitions, and any other sensitive metadata the sanitiser has masked.
The agent runs locally. There is no cloud server receiving your files. If you are in a regulated industry or a GDPR-sensitive environment, the sanitisation gate is configurable — you can choose to also mask GUIDs and remove RLS definitions entirely before the model is reviewed.
What’s Still Being Built
This is a working prototype, not a finished product. I am sharing it now because real-world feedback is more valuable than months of building in isolation.
What is working today:
- Model loading with sanitisation review and approval gate
- DAX generation using your actual schema
- Two-layer validation with automatic retry
- Duplicate measure detection
- Human approval gate before saving
- Persistent measure library with search
- Lineage graph with impact analysis
- Model browser in the sidebar
- Support for any model.bim file
What is still being built:
- System A — a discovery and requirements agent that conducts a structured interview with business stakeholders and produces a semantic model design from scratch
- System C — a full amendment protection layer with regression testing, so changes to existing measures can be validated against known-good baselines before deployment
- Automatic deployment to Power BI via the REST API or XMLA endpoint
- Hosted version for clients who cannot run a local install
- Multi-user support with role-based access
Try It and Tell Me What’s Missing
The repository is public and free to use. You bring your own Anthropic API key — a month of typical usage costs a few euros.
View on GitHub →
